Hydra-7@ADC Status
|
Hydra has been moved to the new data center, updates are at the
Data Center Move page. You can view the list of all the available modules: as an HTML document, or a plain ASCII text file. You can also check the bandwidth between SAO and HDC. You can select to have this page refreshed every 5m, 20m, or 1hr, this one will auto-refresh every 1hr. |
-
Usage

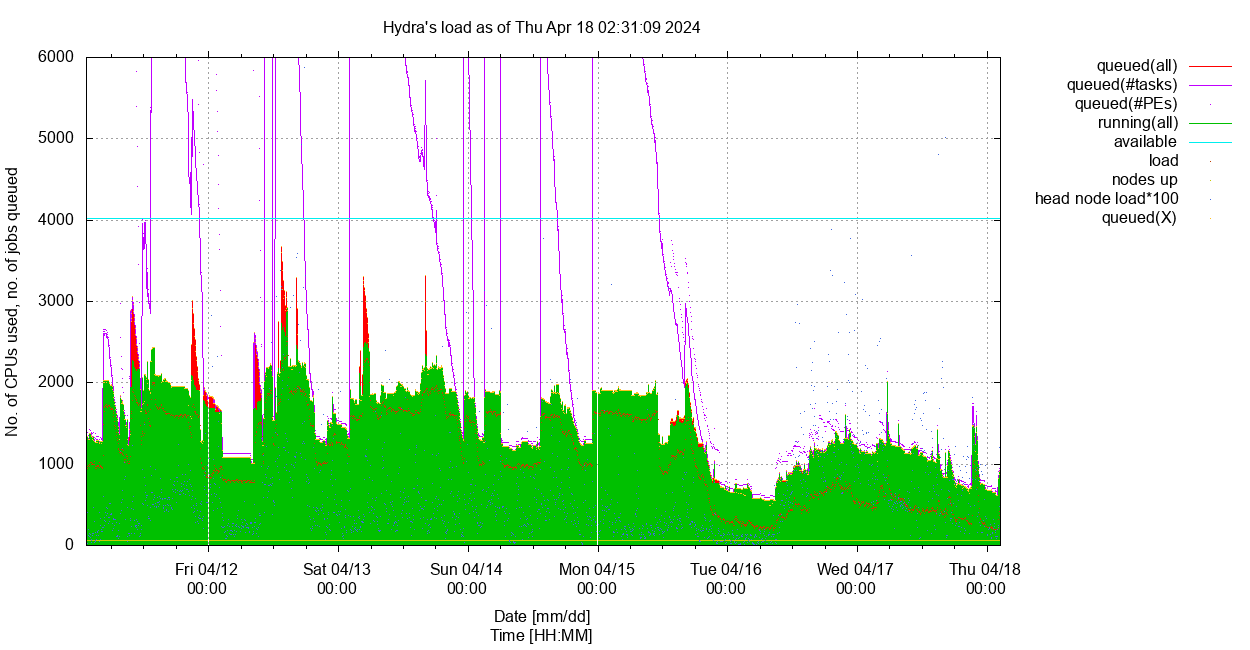
Current snapshot sorted by nodes' . Usage vs time, for length= and user= highlighted.
As of Fri Jun 26 15:27:03 2026: #CPUs/nodes 5396/74, 0 down.
Loads: head node: 0.54, login nodes: 0.61, 0.10, 0.01, 0.00; NSDs: 0.11, 0.00, 0.15, 2.86, 2.81; licenses: none used.
Queues status: 24 disabled, none need attention, none in error state.
21 users with running jobs (slots/jobs):
Current load: 266.8, #running (slots/jobs): 651/126, usage: 12.1%, efficiency: 41.0%
3 users with queued jobs (jobs/tasks/slots):
ggonzale=1 parras=1 whiteae=7/50/150 Total number of queued jobs/tasks/slots: 9/52/152
73 users have/had running or queued jobs over the past 7 days, 97 over the past 15 days. 118 over the past 30 days.
Click on the tabs to view each section, on the plots to view larger versions.
You can view the current cluster snapshot sorted by name, no. cpu, usage, load or memory, and
view the past load for 7, or 15, or 30 days as well as highlight a given user by selecting the corresponding options in the drop down menus.{}
This page was last updated on Friday, 26-Jun-2026 15:32:20 EDT with mk-webpage.pl ver. 7.3/1 (Oct 2025/SGK) in 0:57. -
Warnings
Oversubscribed Jobs
As of Fri Jun 26 15:27:04 EDT 2026 (0 oversubscribed job)
Inefficient Jobs
As of Fri Jun 26 15:27:04 EDT 2026 (12 inefficient jobs, showing no more than 3 per user) Total running (PEs/jobs) = 651/126, 9 queued (jobs), showing only inefficient jobs (cpu% < 33% & age > 1h) for all users. jobID name user age nPEs cpu% queue node taskID 14418505 all_SNaQ flentjeeg +15:03 16 12.8% uThC.q 65-15 14422996 loco-pipe-N187- longk +10:00 32 28.3% mThM.q 93-04 14429150 all_SNaQ10 coellogarridoa +2:23 16 17.4% uThC.q 65-09 14429659 earlgrey zhangy +2:06 12 29.0% lThM.q 76-06 2 14434198 structure_loop hinckleya +1:03 10 10.0% lThC.q 76-08 14435209 run_opt_nrs2 szieba +1:02 60 16.4% lThM.q 75-03 14435212 run_opt_nrs1 szieba +1:02 60 17.7% lThM.q 76-06 14438965 earthaccess_202 ggonzale 06:25 1 7.2% lTIO.sq 64-12 14442611 plat_scaf_fa_YG graujh 04:04 32 2.7% uTxlM.rq 93-06 14442768 hf_bucket_uploa triznam 03:18 12 0.0% sThC.q 76-03 14442771 hf_bucket_uploa triznam 03:14 12 0.0% sThC.q 76-03 14442942 earthaccess_ges ggonzale 01:14 1 4.6% lTIO.sq 64-11 ⇒ Equivalent to 224.2 underused CPUs: 264 CPUs used at 15.1% on average.
Nodes with Excess Load
As of Fri Jun 26 15:27:06 EDT 2026 (2 nodes have a high load, offset=1.5) #slots excess node #CPUs used load load ----------------------------------- 50-01 64 6 8.0 2.0 * 76-04 192 2 3.7 1.7 * Total excess load = 3.7
High Memory Jobs
Statistics
User nSlots memory memory vmem maxvmem ratio Name used reserved used used used [TB] resd/maxvm -------------------------------------------------------------------------------------------------- suttonm 34 9.2% 3.5312 52.0% 2.6367 95.1% 2.7079 2.7086 1.3 graujh 96 26.0% 2.0508 30.2% 0.1076 3.9% 0.1985 0.2729 7.5 longk 32 8.7% 0.6250 9.2% 0.0055 0.2% 0.0773 0.1356 4.6 zhangy 36 9.8% 0.5625 8.3% 0.0076 0.3% 0.0038 0.3095 1.8 morrisseyd 1 0.3% 0.0156 0.2% 0.0043 0.2% 0.0045 0.0046 3.4 szieba 170 46.1% 0.0029 0.0% 0.0116 0.4% 0.3102 2.1869 0.0 ================================================================================================== Total 369 6.7881 2.7733 3.3022 5.6179 1.2
Warnings
25 high memory jobs produced a warning:
1 for graujh 1 for longk 1 for morrisseyd 16 for suttonm 3 for szieba 3 for zhangyDetails for each job can be found here.
-
Breakdown by Queue

Select length:
Current Usage by Queue
Total Limit Fill factor Efficiency sThC.q=46 mThC.q=119 lThC.q=14 uThC.q=80 259 4856 5.3% 98.1% sThM.q=0 mThM.q=33 lThM.q=240 uThM.q=0 273 4616 5.9% 92.8% sTgpu.q=0 mTgpu.q=6 lTgpu.q=1 qgpu.iq=1 8 104 7.7% 115.9% uTxlM.rq=96 96 536 17.9% 2.5% lThMuVM.tq=0 0 384 0.0% lTb2g.q=0 0 2 0.0% lTIO.sq=2 2 34 5.9% 1.8% lTWFM.sq=1 1 18 5.6% 1.9% qrsh.iq=12 12 292 4.1% 2.6% Total: 651
-
Avail Slots/Wait Job(s)
Available Slots
As of Fri Jun 26 15:27:04 EDT 2026 4280 avail(slots), free(load)=4805.4, unresd(mem)=31267.8G, for hgrp=@hicpu-hosts and minMem=1.0G/slot total(nCPU) 4808 total(mem) 36.3T unused(slots) 4280 unused(load) 4805.4 ie: 89.0% 99.9% unreserved(mem) 30.5T unused(mem) 32.7T ie: 84.2% 90.2% unreserved(mem) 7.3G unused(mem) 7.8G per unused(slots)
4144 avail(slots), free(load)=4765.4, unresd(mem)=32696.5G, for hgrp=@himem-hosts and minMem=1.0G/slot total(nCPU) 4768 total(mem) 39.7T unused(slots) 4144 unused(load) 4765.4 ie: 86.9% 99.9% unreserved(mem) 31.9T unused(mem) 35.9T ie: 80.4% 90.5% unreserved(mem) 7.9G unused(mem) 8.9G per unused(slots)
440 avail(slots), free(load)=536.0, unresd(mem)=5963.0G, for hgrp=@xlmem-hosts and minMem=1.0G/slot total(nCPU) 536 total(mem) 7.9T unused(slots) 440 unused(load) 536.0 ie: 82.1% 100.0% unreserved(mem) 5.8T unused(mem) 7.6T ie: 74.0% 96.6% unreserved(mem) 13.6G unused(mem) 17.7G per unused(slots)
96 avail(slots), free(load)=103.8, unresd(mem)=630.2G, for hgrp=@gpu-hosts and minMem=1.0G/slot total(nCPU) 104 total(mem) 0.7T unused(slots) 96 unused(load) 103.8 ie: 92.3% 99.8% unreserved(mem) 0.6T unused(mem) 0.7T ie: 83.5% 91.8% unreserved(mem) 6.6G unused(mem) 7.2G per unused(slots)
GPU Usage
Fri Jun 26 15:27:12 EDT 2026 hostgroup: @gpu-hosts (3 hosts) - --- memory (GB) ---- - #GPU - --------- slots/CPUs --------- hostname - total used resd - a/u - nCPU used load - free unused compute-50-01 - 503.3 30.2 473.1 - 4/4 - 64 6 8.0 - 58 56.0 compute-79-01 - 125.5 15.6 109.9 - 2/1 - 20 1 1.2 - 19 18.8 compute-79-02 - 125.5 16.3 109.2 - 2/1 - 20 1 0.1 - 19 19.9 Total GPU=8, used=6 (75.0%)
Waiting Job(s)
As of Fri Jun 26 15:27:06 EDT 2026 1 job waiting for ggonzale: jobID jobName user age nPEs memReqd queue taskID --------- --------------- ---------------- ------ ---- -------- ------ ------- 14442962 earthaccess_202 ggonzale 00:59 1 lTIO.sq quota rule resource=value/limit %used ------------------- ------------------------------- ------ max_concurrent_jobs_per_u no_concurrent_jobs=2/2 100.0% for ggonzale in queue lTIO.sq io_slots_per_user/1 slots=2/8 25.0% for ggonzale in queue lTIO.sq max_slots_per_user/1 slots=2/840 0.2% for ggonzale ------------------- ------------------------------- ------ 1 job waiting for kimcj: jobID jobName user age nPEs memReqd queue taskID --------- --------------- ---------------- ------ ---- -------- ------ ------- 14443157 nf-WF2_VALIDATE kimcj 00:00 4 quota rule resource=value/limit %used ------------------- ------------------------------- ------ max_concurrent_jobs_per_u no_concurrent_jobs=1/1 100.0% for kimcj in queue lTWFM.sq wfm_slots_per_user/1 slots=1/2 50.0% for kimcj in queue lTWFM.sq max_slots_per_user/1 slots=21/840 2.5% for kimcj max_hC_slots_per_user/1 slots=20/840 2.4% for kimcj in queue sThC.q max_mem_res_per_user/1 mem_res=10.000G/9.985T 0.1% for kimcj in queue uThC.q ------------------- ------------------------------- ------ 1 job waiting for parras: jobID jobName user age nPEs memReqd queue taskID --------- --------------- ---------------- ------ ---- -------- ------ ------- 14442761 dorado_L.teuthr parras 03:29 1 sTgpu.q none running. 7 jobs waiting for whiteae (top 5): jobID jobName user age nPEs memReqd queue taskID --------- --------------- ---------------- ------ ---- -------- ------ ------- 14430718 v4s_mm_2015_01 whiteae +1:19 3 60.0 mTgpu.q 7,8 14430724 v4s_mm20q05 whiteae +1:18 3 60.0 mTgpu.q 1-6:1 14430725 v4s_mm20q04 whiteae +1:18 3 60.0 mTgpu.q 1-25:1 14430726 v4s_mm16v06 whiteae +1:18 3 60.0 mTgpu.q 1-4:1 14430727 v4s_mm16v07 whiteae +1:18 3 60.0 mTgpu.q 1-3:1 quota rule resource=value/limit %used ------------------- ------------------------------- ------ max_gpus_per_user/2 GPUS=4/6 66.7% for whiteae in queue mTgpu.q total_gpus_per_user/1 GPUS=4/8 50.0% for whiteae in queue qgpu.iq max_slots_per_user/1 slots=8/840 1.0% for whiteae max_hC_slots_per_user/1 slots=2/840 0.2% for whiteae in queue sThC.q max_mem_res_per_user/1 mem_res=4.000G/9.985T 0.0% for whiteae in queue uThC.q ------------------- ------------------------------- ------
Overall Quota Usage
quota rule resource=value/limit %used ------------------- ------------------------------- ------ total_gpus/1 GPUS=4/8 50.0% for * in queue mTgpu.q total_mem_res/3 mem_res=2.051T/7.874T 26.0% for * in queue uTxlM.rq total_mem_res/2 mem_res=4.740T/35.78T 13.2% for * in queue uThM.q total_gpus/1 GPUS=1/8 12.5% for * in queue qgpu.iq total_gpus/1 GPUS=1/8 12.5% for * in queue lTgpu.q total_slots/1 slots=651/5960 10.9% for * blast2GO/1 slots=5/110 4.5% for * total_mem_res/1 mem_res=1022.0G/39.94T 2.5% for * in queue uThC.q
-
Memory Usage
Reserved Memory, All High-Memory Queues

Select length:
Current Memory Quota Usage
As of Fri Jun 26 15:27:06 EDT 2026 quota rule resource=value/limit %used filter --------------------------------------------------------------------------------------------------- total_mem_res/1 mem_res=1022.0G/39.94T 2.5% for * in queue uThC.q total_mem_res/2 mem_res=4.740T/35.78T 13.2% for * in queue uThM.q total_mem_res/3 mem_res=2.051T/7.874T 26.0% for * in queue uTxlM.rq
Current Memory Usage by Compute Node, High Memory Nodes Only
hostgroup: @himem-hosts (54 hosts) - ----------- memory (GB) ------------ - --------- slots/CPUs --------- hostname - avail used resd - unused unresd - nCPU used load - free unused compute-65-02 - 503.5 16.4 6.0 - 487.1 497.5 - 64 3 3.0 - 61 61.0 compute-65-03 - 503.5 49.9 100.0 - 453.6 403.5 - 64 3 3.4 - 61 60.6 compute-65-04 - 503.5 12.2 0.0 - 491.3 503.5 - 64 0 1.0 - 64 63.0 compute-65-05 - 503.5 53.4 128.0 - 450.1 375.5 - 64 16 1.2 - 48 62.8 compute-65-06 - 503.5 35.9 96.0 - 467.6 407.5 - 64 1 1.2 - 63 62.8 compute-65-07 - 503.5 89.7 162.0 - 413.8 341.5 - 64 3 3.1 - 61 60.9 compute-65-09 - 503.5 58.4 176.0 - 445.1 327.5 - 64 17 9.2 - 47 54.8 compute-65-10 - 503.5 12.7 4.0 - 490.8 499.5 - 64 2 0.9 - 62 63.1 compute-65-11 - 503.5 13.0 4.0 - 490.5 499.5 - 64 2 2.1 - 62 61.9 compute-65-12 - 503.5 12.2 2.0 - 491.3 501.5 - 64 4 0.8 - 60 63.2 compute-65-13 - 503.5 14.7 4.0 - 488.8 499.5 - 64 2 2.2 - 62 61.8 compute-65-14 - 503.5 64.1 98.0 - 439.4 405.5 - 64 2 2.2 - 62 61.8 compute-65-15 - 503.5 34.3 128.0 - 469.2 375.5 - 64 16 2.2 - 48 61.8 compute-65-16 - 503.5 12.1 2.0 - 491.4 501.5 - 64 1 1.3 - 63 62.7 compute-65-17 - 503.5 116.2 128.0 - 387.3 375.5 - 64 2 2.2 - 62 61.8 compute-65-18 - 503.5 14.9 6.0 - 488.6 497.5 - 64 3 3.2 - 61 60.8 compute-65-19 - 503.5 69.6 66.0 - 433.9 437.5 - 64 2 2.1 - 62 61.9 compute-65-20 - 503.5 159.0 194.0 - 344.5 309.5 - 64 3 3.3 - 61 60.7 compute-65-21 - 503.5 49.8 100.0 - 453.7 403.5 - 64 3 3.1 - 61 60.9 compute-65-22 - 503.5 12.8 4.0 - 490.7 499.5 - 64 2 2.1 - 62 61.9 compute-65-23 - 503.5 12.7 4.0 - 490.8 499.5 - 64 2 2.1 - 62 61.9 compute-65-24 - 503.5 12.7 0.0 - 490.8 503.5 - 64 0 0.9 - 64 63.1 compute-65-25 - 503.5 14.2 0.0 - 489.3 503.5 - 64 0 0.8 - 64 63.2 compute-65-26 - 503.5 52.1 48.0 - 451.4 455.5 - 64 1 1.2 - 63 62.8 compute-65-27 - 503.5 54.3 128.0 - 449.2 375.5 - 64 16 6.2 - 48 57.8 compute-65-28 - 503.5 14.0 0.0 - 489.5 503.5 - 64 0 0.8 - 64 63.2 compute-65-29 - 503.5 11.7 2.0 - 491.8 501.5 - 64 4 0.8 - 60 63.2 compute-65-30 - 503.5 14.2 4.0 - 489.3 499.5 - 64 2 2.3 - 62 61.7 compute-75-01 - 1007.5 56.7 52.1 - 950.8 955.4 - 128 3 4.2 - 125 123.8 compute-75-02 - 1007.5 22.8 14.0 - 984.7 993.5 - 128 7 7.2 - 121 120.8 compute-75-03 - 755.5 63.4 50.0 - 692.1 705.5 - 128 61 12.0 - 67 116.0 compute-75-04 - 755.5 170.0 194.0 - 585.5 561.5 - 128 2 2.4 - 126 125.6 compute-75-05 - 755.5 21.8 4.0 - 733.7 751.5 - 128 51 44.1 - 77 83.9 compute-75-06 - 755.5 17.5 6.0 - 738.0 749.5 - 128 3 3.4 - 125 124.6 compute-75-07 - 755.5 18.0 8.0 - 737.5 747.5 - 128 4 4.4 - 124 123.6 compute-76-03 - 1007.4 20.3 48.5 - 987.1 958.9 - 128 24 1.9 - 104 126.2 compute-76-04 - 1007.4 18.0 4.0 - 989.4 1003.4 - 128 2 2.5 - 126 125.5 compute-76-05 - 1007.4 16.5 2.0 - 990.9 1005.4 - 128 1 1.8 - 127 126.2 compute-76-06 - 1007.4 298.6 514.0 - 708.8 493.4 - 128 75 19.8 - 53 108.2 compute-76-07 - 1007.4 140.0 320.0 - 867.4 687.4 - 128 66 25.5 - 62 102.5 compute-76-08 - 1007.4 227.4 498.0 - 780.0 509.4 - 128 23 5.7 - 105 122.3 compute-76-09 - 1007.4 15.4 192.0 - 992.0 815.4 - 128 12 3.2 - 116 124.8 compute-76-10 - 1007.4 228.1 322.0 - 779.3 685.4 - 128 18 9.8 - 110 118.2 compute-76-11 - 1007.4 15.9 2.0 - 991.5 1005.4 - 128 4 1.1 - 124 126.9 compute-76-12 - 1007.4 15.8 0.0 - 991.6 1007.4 - 128 0 1.8 - 128 126.2 compute-76-13 - 1007.4 178.6 226.0 - 828.8 781.4 - 128 6 5.6 - 122 122.4 compute-76-14 - 1007.4 240.1 260.0 - 767.3 747.4 - 128 3 3.4 - 125 124.6 compute-84-01 - 881.1 167.5 292.0 - 713.6 589.1 - 112 5 5.0 - 107 107.0 compute-93-01 - 503.8 107.5 114.0 - 396.3 389.8 - 64 3 3.1 - 61 60.9 compute-93-02 - 755.6 215.4 290.0 - 540.2 465.6 - 72 4 4.0 - 68 68.0 compute-93-03 - 755.6 196.6 226.0 - 559.0 529.6 - 72 3 3.0 - 69 69.0 compute-93-04 - 755.6 78.6 640.0 - 677.0 115.6 - 72 32 13.2 - 40 58.8 compute-93-05 - 2016.3 78.8 1500.0 - 1937.5 516.3 - 96 64 1.1 - 32 95.0 compute-93-06 - 3023.9 146.3 600.1 - 2877.6 2423.8 - 56 32 1.1 - 24 54.9 ======= ===== ====== ==== ==== ===== Totals 40671.2 3862.8 7972.7 4768 620 255.2 ==> 9.5% 19.6% ==> 13.0% 5.4% Most unreserved/unused memory (2423.8/2877.6GB) is on compute-93-06 with 24/54.9 slots/CPUs free/unused. hostgroup: @xlmem-hosts (4 hosts) - ----------- memory (GB) ------------ - --------- slots/CPUs --------- hostname - avail used resd - unused unresd - nCPU used load - free unused compute-76-01 - 1511.4 13.5 -0.0 - 1497.9 1511.4 - 192 0 0.0 - 192 192.0 compute-76-02 - 1511.4 39.5 -0.0 - 1471.9 1511.4 - 192 0 0.3 - 192 191.7 compute-93-05 - 2016.3 78.8 1500.0 - 1937.5 516.3 - 96 64 1.1 - 32 95.0 compute-93-06 - 3023.9 146.3 600.1 - 2877.6 2423.8 - 56 32 1.1 - 24 54.9 ======= ===== ====== ==== ==== ===== Totals 8063.0 278.1 2100.0 536 96 2.4 ==> 3.4% 26.0% ==> 17.9% 0.4% Most unreserved/unused memory (2423.8/2877.6GB) is on compute-93-06 with 24/54.9 slots/CPUs free/unused.
Past Memory Usage vs Memory Reservation
Past memory use in hi-mem queues between 06/17/26 and 06/24/26 queues: ?ThM.q ----------- total --------- -------------------- mean -------------------- user no. of elapsed time eff. reserved maxvmem average ratio name jobs/slots [d] [%] [GB] [GB] [GB] resd/maxvmem --------------- -------------- ------------ ----- --------- -------- --------- ------------ flentjeeg 1/6 0.00 12.7 960.0 0.0 0.0 0.0 macdonaldk 3/36 0.00 70.4 288.0 1.8 1.3 159.3 > 2.5 collinsa 32/96 0.03 34.9 59.8 14.4 1.9 4.2 > 2.5 coellogarridoa 11/42 0.03 223.2 1052.5 403.7 17.0 2.6 > 2.5 kistlerl 21/21 0.05 139.2 64.0 23.7 7.9 2.7 > 2.5 graujh 1/56 0.06 68.3 30.0 1000.3 49.2 0.0 mancusij 1/1 0.09 360.9 450.0 186.4 0.9 2.4 lealc 3/50 0.13 65.9 201.1 42.7 14.0 4.7 > 2.5 farmers 10/64 0.13 82.7 96.1 5.6 4.6 17.0 > 2.5 mcgowenm 3/3 0.18 99.6 32.0 28.2 14.9 1.1 willishr 170/1372 0.33 105.4 40.2 4.9 4.5 8.2 > 2.5 auscavitchs 2/20 0.39 63.6 300.0 56.7 25.7 5.3 > 2.5 niez 1/4 0.45 365.3 96.0 8.6 1.5 11.1 > 2.5 pradon 8/512 0.48 56.6 12.0 197.0 136.1 0.1 atkinsonga 5/83 0.48 138.7 234.0 59.6 35.6 3.9 > 2.5 sylvain 9/96 0.73 99.6 29.3 17.8 1.6 1.6 palmerem 940/940 1.26 103.3 285.5 6.8 6.1 41.8 > 2.5 suttonm 15/15 1.93 99.3 148.8 149.1 19.5 1.0 campanam 28/153 2.11 97.6 54.4 9.6 4.5 5.7 > 2.5 przelomskan 6/6 2.40 125.6 28.2 27.4 8.7 1.0 macguigand 672/1512 3.88 41.7 146.5 23.3 1.6 6.3 > 2.5 sandoval-velascom 547/547 4.45 100.1 72.0 4.6 1.7 15.7 > 2.5 bourkeb 32/382 4.91 226.0 261.6 216.3 63.0 1.2 byerlyp 11/55 5.10 48.6 99.6 45.0 38.4 2.2 horowitzj 3658/3658 5.16 87.5 16.0 2.5 1.3 6.4 > 2.5 szieba 96/4410 7.85 66.0 9.1 144.8 7.4 0.1 zhangy 12/142 9.33 43.1 227.7 202.2 3.0 1.1 peresph 26/200 17.85 20.9 169.3 94.4 33.8 1.8 santosbe 162/2412 52.73 18.9 303.0 45.1 13.5 6.7 > 2.5 morrisseyd 1504/1504 159.09 98.9 16.0 5.1 3.3 3.1 > 2.5 --------------- -------------- ------------ ----- --------- -------- --------- ------------ all 7990/18398 281.60 77.2 98.6 35.4 9.3 2.8 > 2.5 --- queues: ?TxlM.rq ----------- total --------- -------------------- mean -------------------- user no. of elapsed time eff. reserved maxvmem average ratio name jobs/slots [d] [%] [GB] [GB] [GB] resd/maxvmem --------------- -------------- ------------ ----- --------- -------- --------- ------------ graujh 3/128 1.37 36.1 600.0 551.0 198.4 1.1 --------------- -------------- ------------ ----- --------- -------- --------- ------------ all 3/128 1.37 36.1 600.0 551.0 198.4 1.1
-
Resource Limits
Limit slots for all users together users * to slots=5960 users * queues sThC.q,lThC.q,mThC.q,uThC.q to slots=5176 users * queues sThM.q,mThM.q,lThM.q,uThM.q to slots=4680 users * queues uTxlM.rq to slots=536 users * queues sTgpu.q,mTgpu.q,lTgpu.q to slots=104 Limit total reserved memory for all users per queue type users * queues sThC.q,mThC.q,lThC.q,uThC.q to mem_res=40902G users * queues sThM.q,mThM.q,lThM.q,uThM.q to mem_res=36637G users * queues uTxlM.rq to mem_res=8063G Limit slots/user for all queues users {*} to slots=840 Limit slots/user for hiMem queues users {*} queues {sThM.q} to slots=840 users {*} queues {mThM.q} to slots=585 users {*} queues {lThM.q} to slots=390 users {*} queues {uThM.q} to slots=73 Limit slots/user for xlMem restricted queue users {*} queues {uTxlM.rq} to slots=536 Limit GPUs for all users in GPU queues to the avail no of GPUs users * queues {sTgpu.q,mTgpu.q,lTgpu.q,qgpu.iq} to GPUS=8 Limit to set aside a slot for blast2GO users * queues !lTb2g.q hosts {@b2g-hosts} to slots=110 users * queues lTb2g.q hosts {@b2g-hosts} to slots=1 users {*} queues lTb2g.q hosts {@b2g-hosts} to slots=1 Limit GPUs per user in all the GPU queues users {@gpu-power-users} queues sTgpu.q,mTgpu.q,lTgpu.q, qgpu.iq to GPUS=8 users {*} queues sTgpu.q,mTgpu.q,lTgpu.q,qgpu.iq to GPUS=4 Limit GPUs per user in each GPU queues users {@gpu-power-users} queues {sTgpu.q} to GPUS=8 users {@gpu-power-users} queues {mTgpu.q} to GPUS=6 users {@gpu-power-users} queues {lTgpu.q} to GPUS=4 users {@gpu-power-users} queues {qgpu.iq} to GPUS=2 users {*} queues {sTgpu.q} to GPUS=4 users {*} queues {mTgpu.q} to GPUS=3 users {*} queues {lTgpu.q} to GPUS=2 users {*} queues {qgpu.iq} to GPUS=1 Limit total number of idl licenses per user users {*} to idlrt_license=102 Limit slots for io queue per user users {*} queues {lTIO.sq} to slots=8 Limit slots for io queue per user users {*} queues {lTWFM.sq} to slots=2 Limit slots/user for interactive (qrsh) queues users {*} queues {qrsh.iq} to slots=64 Limit reserved memory per user for specific queues users {*} queues sThC.q,mThC.q,lThC.q,uThC.q to mem_res=10225G users {*} queues sThM.q,mThM.q,lThM.q,uThM.q to mem_res=9159G users {*} queues uTxlM.rq to mem_res=8063G Limit slots/user in hiCPU queues users {*} queues {sThC.q} to slots=840 users {*} queues {mThC.q} to slots=640 users {*} queues {lThC.q} to slots=431 users {*} queues {uThC.q} to slots=143 Limit the number of concurrent jobs per user for some queues users {*} queues {uTxlM.rq} to no_concurrent_jobs=3 users {*} queues {lTIO.sq} to no_concurrent_jobs=2 users {*} queues {lTWFM.sq} to no_concurrent_jobs=1 users {*} queues {qrsh.iq} to no_concurrent_jobs=12 users {*} queues {qgpu.iq} to no_concurrent_jobs=1
-
Disk Usage & Quota
As of Fri Jun 26 11:06:02 EDT 2026
Disk Usage
Filesystem Size Used Avail Capacity Mounted on netapp-fas83:/vol_home 22.36T 20.05T 2.31T 90%/13% /home netapp-fas83-n01:/vol_data_public 332.50T 119.38T 213.12T 36%/2% /data/public gpfs02:public 800.00T 596.18T 203.82T 75%/36% /scratch/public gpfs02:nmnh_bradys 25.00T 20.68T 4.32T 83%/59% /scratch/bradys gpfs02:nmnh_kistlerl 120.00T 92.38T 27.62T 77%/14% /scratch/kistlerl gpfs02:nmnh_meyerc 25.00T 21.18T 3.82T 85%/8% /scratch/meyerc gpfs02:nmnh_corals 60.00T 55.50T 4.50T 93%/24% /scratch/nmnh_corals gpfs02:nmnh_ggi 130.00T 36.46T 93.54T 29%/15% /scratch/nmnh_ggi gpfs02:nmnh_lab 25.00T 12.89T 12.11T 52%/12% /scratch/nmnh_lab gpfs02:nmnh_mammals 35.00T 29.85T 5.15T 86%/39% /scratch/nmnh_mammals gpfs02:nmnh_mdbc 60.00T 51.81T 8.19T 87%/26% /scratch/nmnh_mdbc gpfs02:nmnh_ocean_dna 90.00T 73.75T 16.25T 82%/6% /scratch/nmnh_ocean_dna gpfs02:nzp_ccg 145.00T 30.49T 114.51T 22%/42% /scratch/nzp_ccg gpfs01:ocio_dpo 10.00T 2.59T 7.41T 26%/1% /scratch/ocio_dpo gpfs01:ocio_ids 5.00T 0.00G 5.00T 0%/1% /scratch/ocio_ids gpfs02:pool_kozakk 12.00T 10.67T 1.33T 89%/2% /scratch/pool_kozakk gpfs02:pool_sao_access 50.00T 4.79T 45.21T 10%/9% /scratch/pool_sao_access gpfs02:pool_sao_rtdc 20.00T 908.33G 19.11T 5%/1% /scratch/pool_sao_rtdc gpfs02:sao_atmos 350.00T 274.83T 75.17T 79%/12% /scratch/sao_atmos gpfs02:sao_cga 25.00T 9.44T 15.56T 38%/28% /scratch/sao_cga gpfs02:sao_tess 50.00T 23.25T 26.75T 47%/70% /scratch/sao_tess gpfs02:scbi_gis 200.00T 142.10T 57.90T 72%/8% /scratch/scbi_gis gpfs02:nmnh_schultzt 35.00T 25.07T 9.93T 72%/75% /scratch/schultzt gpfs02:serc_cdelab 35.00T 8.85T 26.15T 26%/5% /scratch/serc_cdelab gpfs02:stri_ap 25.00T 21.80T 3.20T 88%/2% /scratch/stri_ap gpfs01:sao_sylvain 145.00T 44.65T 100.35T 31%/23% /scratch/sylvain gpfs02:usda_sel 25.00T 15.73T 9.27T 63%/36% /scratch/usda_sel gpfs02:wrbu 50.00T 45.03T 4.97T 91%/14% /scratch/wrbu nas1:/mnt/pool/public 175.00T 108.00T 67.00T 62%/1% /store/public nas1:/mnt/pool/nmnh_bradys 40.00T 14.58T 25.42T 37%/1% /store/bradys nas2:/mnt/pool/n1p3/nmnh_ggi 90.00T 36.28T 53.72T 41%/1% /store/nmnh_ggi nas2:/mnt/pool/nmnh_lab 40.00T 16.61T 23.39T 42%/1% /store/nmnh_lab nas2:/mnt/pool/nmnh_ocean_dna 70.00T 33.93T 36.07T 49%/1% /store/nmnh_ocean_dna nas1:/mnt/pool/nzp_ccg 265.00T 127.30T 137.70T 49%/1% /store/nzp_ccg nas2:/mnt/pool/nzp_cec 40.00T 20.71T 19.29T 52%/1% /store/nzp_cec nas2:/mnt/pool/n1p2/ocio_dpo 20.00T 0.00G 20.00T 1%/1% /store/ocio_dpo nas2:/mnt/pool/n1p1/sao_atmos 750.00T 469.53T 280.47T 63%/1% /store/sao_atmos nas2:/mnt/pool/n1p2/nmnh_schultzt 80.00T 24.96T 55.04T 32%/1% /store/schultzt nas1:/mnt/pool/sao_sylvain 50.00T 9.64T 40.36T 20%/1% /store/sylvain nas1:/mnt/pool/wrbu 80.00T 10.02T 69.98T 13%/1% /store/wrbu nas1:/mnt/pool/admin 20.00T 8.06T 11.94T 41%/1% /store/admin
You can view plots of disk use vs time, for the past 7, 30, or 120 days; as well as plots of disk usage by user, or by device (for the past 90 or 240 days respectively).Notes
Capacity shows % disk space full and % of inodes used.
When too many small files are written on a disk, the file system can become full because it is unable to keep track of new files.
The % of inodes should be lower or comparable to the % of disk space used.
If it is much larger, the disk can become unusable before it gets full.
Disk Quota Report
Volume=NetApp:vol_data_public, mounted as /data/public -- disk -- -- #files -- default quota: 4.50TB/10.0M Disk usage %quota usage %quota name, affiliation - username (indiv. quota) -------------------- ------- ------ ------ ------ ------------------------------------------- /data/public 4.14TB 92.0% 5.07M 50.7% Alicia Talavera, NMNH - talaveraa Volume=NetApp:vol_home, mounted as /home -- disk -- -- #files -- default quota: 384.0GB/10.0M Disk usage %quota usage %quota name, affiliation - username (indiv. quota) -------------------- ------- ------ ------ ------ ------------------------------------------- /home 384.5GB 100.1% 0.10M 1.0% *** Alison Fowler, NZCBI - fowlera /home 375.5GB 97.8% 0.09M 0.9% *** Rebeka Tamasi Bottger, SAO/OIR - rbottger /home 363.6GB 94.7% 0.27M 2.7% Juan Uribe, NMNH - uribeje /home 348.5GB 90.8% 2.94M 29.4% Brian Bourke, WRBU - bourkeb /home 329.1GB 85.7% 0.00M 0.0% Allan Cabrero, NMNH - cabreroa Volume=GPFS:scratch_public, mounted as /scratch/public -- disk -- -- #files -- default quota: 15.00TB/39.8M Disk usage %quota usage %quota name, affiliation - username (indiv. quota) -------------------- ------- ------ ------ ------ ------------------------------------------- /scratch/public 17.20TB 114.7% 2.78M 7.0% *** Ting Wang, NMNH - wangt2 /scratch/public 15.00TB 100.0% 1.72M 4.3% *** Juan Uribe, NMNH - uribeje /scratch/public 15.00TB 100.0% 21.59M 54.2% *** Zelong Nie, NMNH - niez /scratch/public 13.70TB 91.3% 36.29M 91.1% Alberto Coello Garrido, NMNH - coellogarridoa /scratch/public 13.60TB 90.7% 10.42M 26.2% Michael Trizna, NMNH/BOL - triznam /scratch/public 13.50TB 90.0% 2.32M 5.8% Solomon Chak, SERC - chaks /scratch/public 13.50TB 90.0% 0.39M 1.0% Jose Grau, SCBI - graujh /scratch/public 13.40TB 89.3% 0.58M 1.5% Molly Hagemann, NZCBI - hagemannm /scratch/public 13.30TB 88.7% 0.56M 1.4% Herman Wirshing, NMNH/IZ - wirshingh /scratch/public 13.20TB 88.0% 0.00M 0.0% Joseph Mancusi, NZCBI - mancusij /scratch/public 13.20TB 88.0% 4.20M 10.5% Kevin Mulder, NZP - mulderk /scratch/public 13.10TB 87.3% 0.80M 2.0% Henrique Figueiro, SCBI - figueiroh Volume=GPFS:scratch_stri_ap, mounted as /scratch/stri_ap -- disk -- -- #files -- default quota: 5.00TB/12.6M Disk usage %quota usage %quota name, affiliation - username (indiv. quota) -------------------- ------- ------ ------ ------ ------------------------------------------- /scratch/stri_ap 19.60TB 392.0% 0.25M 0.0% *** Carlos Arias, STRI - ariasc Volume=NAS:store_public, mounted as /store/public -- disk -- -- #files -- default quota: 0.0MB/0.0M Disk usage %quota usage %quota name, affiliation - username (indiv. quota) -------------------- ------- ------ ------ ------ ------------------------------------------- /store/public 4.80TB 96.1% - - *** Madeline Bursell, OCIO - bursellm (5.0TB/0M) /store/public 4.73TB 94.6% - - Zelong Nie, NMNH - niez (5.0TB/0M) /store/public 4.51TB 90.1% - - Alicia Talavera, NMNH - talaveraa (5.0TB/0M) /store/public 4.39TB 87.8% - - Mirian Tsuchiya, NMNH/Botany - tsuchiyam (5.0TB/0M)
SSD Usage
Node -------------------------- /ssd ------------------------------- Name Size Used Avail Use% | Resd Avail Resd% | Resd/Used 64-18 3.49T 24.6G 3.47T 0.7% | 0.0G 3.49T 0.0% | 0.00 65-02 3.49T 65.5G 3.43T 1.8% | 0.0G 3.49T 0.0% | 0.00 65-03 3.49T 64.5G 3.43T 1.8% | 0.0G 3.49T 0.0% | 0.00 65-04 3.49T 65.5G 3.43T 1.8% | 0.0G 3.49T 0.0% | 0.00 65-05 3.49T 64.5G 3.43T 1.8% | 0.0G 3.49T 0.0% | 0.00 65-06 3.49T 63.5G 3.43T 1.8% | 0.0G 3.49T 0.0% | 0.00 65-07 3.49T 24.6G 3.47T 0.7% | 0.0G 3.49T 0.0% | 0.00 65-10 1.75T 62.5G 1.68T 3.5% | 0.0G 1.75T 0.0% | 0.00 65-11 1.75T 52.2G 1.69T 2.9% | 0.0G 1.75T 0.0% | 0.00 65-12 1.75T 12.3G 1.73T 0.7% | 0.0G 1.75T 0.0% | 0.00 65-13 1.75T 53.2G 1.69T 3.0% | 0.0G 1.75T 0.0% | 0.00 65-14 1.75T 53.2G 1.69T 3.0% | 0.0G 1.75T 0.0% | 0.00 65-15 1.75T 12.3G 1.73T 0.7% | 0.0G 1.75T 0.0% | 0.00 65-16 1.75T 53.2G 1.69T 3.0% | 0.0G 1.75T 0.0% | 0.00 65-17 1.75T 12.3G 1.73T 0.7% | 0.0G 1.75T 0.0% | 0.00 65-18 1.75T 53.2G 1.69T 3.0% | 0.0G 1.75T 0.0% | 0.00 65-19 1.75T 53.2G 1.69T 3.0% | 0.0G 1.75T 0.0% | 0.00 65-20 1.75T 159.7G 1.59T 8.9% | 0.0G 1.75T 0.0% | 0.00 65-21 1.75T 53.2G 1.69T 3.0% | 0.0G 1.75T 0.0% | 0.00 65-22 1.75T 53.2G 1.69T 3.0% | 0.0G 1.75T 0.0% | 0.00 65-23 1.75T 53.2G 1.69T 3.0% | 0.0G 1.75T 0.0% | 0.00 65-24 1.75T 52.2G 1.69T 2.9% | 0.0G 1.75T 0.0% | 0.00 65-25 1.75T 52.2G 1.69T 2.9% | 0.0G 1.75T 0.0% | 0.00 65-26 1.75T 52.2G 1.69T 2.9% | 0.0G 1.75T 0.0% | 0.00 65-27 1.75T 53.2G 1.69T 3.0% | 0.0G 1.75T 0.0% | 0.00 65-28 1.75T 12.3G 1.73T 0.7% | 0.0G 1.75T 0.0% | 0.00 65-29 1.75T 52.2G 1.69T 2.9% | 0.0G 1.75T 0.0% | 0.00 65-30 1.75T 54.3G 1.69T 3.0% | 0.0G 1.75T 0.0% | 0.00 75-01 5.24T 78.8G 5.16T 1.5% | 0.0G 5.24T 0.0% | 0.00 75-03 6.98T 90.1G 6.89T 1.3% | 0.0G 6.98T 0.0% | 0.00 75-04 6.98T 90.1G 6.89T 1.3% | 0.0G 6.98T 0.0% | 0.00 75-05 6.98T 50.2G 6.93T 0.7% | 0.0G 6.98T 0.0% | 0.00 75-06 6.98T 50.2G 6.93T 0.7% | 0.0G 6.98T 0.0% | 0.00 76-01 1.75T 12.3G 1.73T 0.7% | 0.0G 1.75T 0.0% | 0.00 76-03 1.75T 53.2G 1.69T 3.0% | 0.0G 1.75T 0.0% | 0.00 76-04 1.75T 52.2G 1.69T 2.9% | 0.0G 1.75T 0.0% | 0.00 76-05 1.75T 53.2G 1.69T 3.0% | 0.0G 1.75T 0.0% | 0.00 76-06 1.75T 96.3G 1.65T 5.4% | 0.0G 1.75T 0.0% | 0.00 76-07 1.75T 12.3G 1.73T 0.7% | 0.0G 1.75T 0.0% | 0.00 76-08 1.75T 94.2G 1.65T 5.3% | 0.0G 1.75T 0.0% | 0.00 76-09 1.75T 93.2G 1.65T 5.2% | 0.0G 1.75T 0.0% | 0.00 76-10 1.75T 53.2G 1.69T 3.0% | 0.0G 1.75T 0.0% | 0.00 76-11 1.75T 53.2G 1.69T 3.0% | 0.0G 1.75T 0.0% | 0.00 76-12 1.75T 12.3G 1.73T 0.7% | 0.0G 1.75T 0.0% | 0.00 76-13 1.75T 99.3G 1.65T 5.6% | 0.0G 1.75T 0.0% | 0.00 76-14 1.75T 55.3G 1.69T 3.1% | 0.0G 1.75T 0.0% | 0.00 79-01 7.28T 51.2G 7.22T 0.7% | 0.0G 7.28T 0.0% | 0.00 79-02 7.28T 51.2G 7.22T 0.7% | 0.0G 7.28T 0.0% | 0.00 93-06 1.64T 11.3G 1.62T 0.7% | 0.0G 1.64T 0.0% | 0.00 --------------------------------------------------------------- Total 133.1T 2.59T 130.5T 1.9% | 0.0G 133.1T 0.0% | 0.00
Note: the disk usage and the quota report are compiled 4x/day, the SSD usage is updated every 10m.