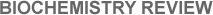
Life may seem biologically, socially, and culturally complex, but physically and chemically it’s rather simple. When reduced to its component parts, the basic ingredients of life—any life, from bacteria to whales, and including humans too—are hardly more exotic than two dozen molecules. So to understand the essential properties of life, we need not examine an organism as messy as the entire human body; the molecular nature of contemporary life will do. This is the realm of biochemistry—the study of chemical processes in living organisms.
All living systems are made of cells, the simplest form of material substance having the common attributes of life—birth, metabolism, and death. From primitive microbes to intelligent humans, the basic unit is the cell. To appreciate chemical evolution—the changes that occurred among atoms and molecules in order to produce life in this, the fifth, CHEMICAL EPOCH—we need only consider the construction of a cell.
Cells are minute, ~100 times smaller than a millimeter (or 10 microns across), thus invisible to the naked eye. Sketched in Figure 5.3, nearly 1000 such cells would fit within the period at the end of this sentence. A microscopic view shows a central nucleus to be the most complex part of most (but not all) cells. Containing trillions of atoms and molecules, such biological nuclei should not be confused with the much smaller atomic nuclei produced in the cores of stars. Resembling the yolk of an egg, a cell’s biological nucleus is surrounded by a thick, fluidic cytoplasm of less complexity. The whole unicell is encased within a semi-permeable membrane through which atoms and molecules can pass in and out.
| FIGURE 5.3 — Schematic, though simplified, diagram of a single cell, whose diameter is ~10 microns. This cell is already quite complex as it has a nucleus as well as cytoplasm encased in a membrane; simpler cells have no well-defined nucleus. |
Cells, then, are the simplest form of life—the “bricks” of anatomical structure. However, they’re vastly more complex than the simplest form of matter—elementary particles within atoms. In fact, it’s worth stressing that simple cells are more complex than any known type of inanimate matter, lending credence to the evolutionary progression from simplicity to complexity, from matter to life, along the arrow of time.
One of the primary creatures of all, the amoeba, consists of only a single cell. More advanced organisms usually contain many additional cells, often huge clusters of them. A grown human, for example, harbors ~1014 (i.e., a hundred trillion) microscopic cells in the guts, skin, bones, hair, muscles, and every other part of our bodies (though only a tenth, or ten trillion, of these are true human cells, the other 90% being bacterial cells that eerily inhabit our bodies). Each one of these cells furthermore contains very large numbers—trillions or more—of atoms and molecules. The density of basic matter in advanced life forms is indeed great— ~200 million cells/cm3 —which is why some researchers regard cellular compactness as a rudimentary measure of complexity. But surely there’s more to the idea of complexity than just structural density.
Over the course of time, even as brief as a second, large numbers of cells are destroyed owing to the normal process of aging and death. All living systems are nonetheless able to maintain a reasonably constant size and appearance throughout adulthood. Thus, while some cells are dying, others must be forming. Our bodies and those of all other living creatures continually manufacture cell nuclei, cytoplasm, and membrane to sustain themselves throughout life. They do so by means of a curious interaction between the two basic building blocks of life.
Amino Acids The dominant, foundational ingredient of the cytoplasm in any living system is protein, a word derived from Greek and meaning “of first importance.” Not the name of a particular substance, rather the term for an entire class of molecules, proteins contain large quantities of the element carbon. In fact, 50% of the dry weight of our bodies is carbon, largely because each of us harbors tens of thousands of proteins.
Such animate, “organic” substances strongly contrast with things obviously not living, such as a slab of concrete or a pinch of salt. Those things are said to be “inorganic,” for they’re made mostly of minerals. Inanimate objects have no proteins and their carbon content often amounts to less than ~0.1% of their total weight.
So, carbon atoms play a prominent role in living systems. They play a vital role in the construction of proteins. Unquestionably, carbon is the single most important element in our lives.
Of what are the proteins composed? Besides having lots of carbon, is there a common denominator among the myriad different proteins found throughout the wide spectrum of cells alive today? The answer is yes, for experiments have shown that proteins are made of a rather small group of molecules, called amino acids. Although chemists have synthesized many such acids artificially, only 20 (plus two rare ones) of these structural units comprise the millions of proteins found in Earth’s life—not just human life; all life. Amino acids are one of the two basic building blocks of life.
Amino acids are not overly complicated substances. Figure 5.4 is a schematic diagram of the simplest one, glycine, a molecular cluster of 5 atoms of hydrogen, 2 of carbon, 2 of oxygen, and 1 of nitrogen. All 20 kinds of amino acids have the same backbone, or inner structure, so marked in the figure. Each of these atoms is held to the others by electromagnetic forces of attraction—cohesive chemical bonds involving electric charges. The most complex amino acid is tryptophan, composed of 12 hydrogens, 11 carbons, 2 oxygens, and 2 nitrogens.
| FIGURE 5.4 — Schematic diagram of the molecular backbone for all 20 kinds of amino acids. The "side chain" can represent any one of 20 different types of molecules, each type granting an amino acid its chemical character. |
As shown in Figure 5.4, a single hydrogen atom is attached to one side of the central carbon atom. To another side, a carboxyl group of atoms, designed COOH, comprises a 4-atom molecule that is itself bonded together by electric charges. An amino group of atoms, NH2, is also attached to the central carbon atom; this molecule forms the basis of the more well-known ammonia molecule, NH3.
A fourth molecule attaches to another side of the central carbon atom. Here we call it a "side chain," although there’s no specific atom or molecule having that name. Instead, the side chain is shorthand notation for any one of 20 different molecules that can attach themselves to the backbone. For the simplest amino acid, known as glycine, the side chain is the simplest possible attachment—hydrogen, H. A slightly more complex amino acid, alanine, has a side chain made of the methyl molecule, CH3. Figure 5.5 compiles all the amino acid molecules that participate in life, showing the structure of the side chain in each case.
 |
FIGURE 5.5 — A complete list of the 20 natural amino acids that participate in life. Each one has an identical structure, except for the side chain (at left of each) that differs for each kind of amino acid. |
These 20 molecules are the only kinds of matter of which all proteins are constructed. Since the backbone is identical for all amino acids, the different side chains must be responsible for the character of the amino acid molecules. In fact, the physical and chemical behavior of an amino acid depends largely on the structure of its side chain.
In principle, the simplest possible protein should theoretically be the combination of two glycine amino acids. As suggested by Figure 5.6, an electromagnetic link would couple them, provided that a hydrogen (H) atom is removed from one glycine, and hydroxyl (or oxygenated hydrogen, OH) from the other. This amounts to an extraction of a water molecule—a process called dehydration condensation—and guarantees a strong chemical bond between the two glycines.
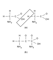 |
FIGURE 5.6 — When water (H20) is removed (a), glycine amino acids can be linked together to form a simple "protein" (b). Real proteins are bigger, but do combine their amino acids in this same way. |
In practice, life is more complicated and biochemists are unaware of any real protein as simple as this, for such a two-acid molecule (or “dipeptide”) exhibits none of the function—or job assignment—normally associated with proteins. One of the smallest known proteins in real life is insulin, with 51 amino acids linked together like pearls on a necklace. In comparison with the atoms featured in earlier epochs, this simplest amino acid has a mass equal to several thousand hydrogen atoms.
Figure 5.7 shows a model of another well-known protein, hemoglobin, a key component of human blood cells. Containing nearly 600 amino acids, hemoglobin incorporates in its structure 19 of the 20 different types of amino acids that normally participate in life. The biochemical function of hemoglobin (as well as all other proteins) is highly specific, much like blood transfusions of one type cannot serve as a substitute for blood of another type. The differences among various blood types result partly from the ordering of the amino acids along the protein. Thus, the physical and chemical behavior of a protein—just a long, stringy accumulation of amino acids—depends not only on the number of amino acids, but also on the order of the acids comprising that protein.
| FIGURE 5.7 — A model of the hemoglobin protein found in human blood. (Harvard) |
in a larger realm, proteins give some function to cells, and cells in turn to entire living organisms. Ultimately, the overall character of life depends on the kind and sequence of amino acids. Only this numbering and ordering distinguishes a human from a mouse, or a duck from a daisy. Since the amino acids are few and relatively simple, the basic nature of life itself cannot be overly complex—at least at the microscopic level.
Nucleotide Bases Mindful of the molecular structure of proteins, we return to our original concern: How are proteins made within organisms in order to keep them alive? Specifically, what chemical process serves to combine amino acids in order to replenish the dead cytoplasm in all living systems? Whatever that process, it must be of central importance since the production of protein is absolutely vital to an organism’s well-being—not any random collection of proteins, but exactly the right kinds of proteins, with their amino acids strung along in precisely the correct order. To appreciate how protein is constructed with such precise numbering and sequencing, we defer to the nucleic acids, another of life’s basic ingredients.
Nucleic acids, like proteins, are long chainlike groups of molecules, most of them also rich in carbon. Their name derives from the fact that these acids were first found in the biological nuclei of cells. Though chemists know of a large variety of them, the nucleic acids, again like proteins, are made of only a small number of key compounds. Called nucleotide bases, these are the second group of life’s building blocks. The biochemical role of the bases is best illustrated by the most famous of all nucleic acids—deoxyribonucleic acid, alias DNA.
Most of the DNA molecule is made of a long string of 4 fundamental bases—adenine, cytosine, guanine, and thymine—that repeat over and over. A fifth nucleotide base, uracil, is used in the construction of other nucleic acids, though not in DNA. These 5 kinds of bases play much the same role for nucleic acids as do the 20 kinds of amino acids for proteins. Each nucleotide base is only slightly more complex than the amino acids, also being a molecular assemblage of carbon, hydrogen, oxygen, and nitrogen atoms—“CHON,” for short. Parts of the bases bend around and attach to themselves in a ring, thereby becoming a little more stable. Figure 5.8 shows a schematic diagram of the structure of the DNA molecule and a photograph of a model of it.
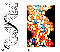 |
FIGURE 5.8 — Diagram (a) and model (b) of the DNA molecule, the most famous of the nucleic acids. The symbols A, C, G, and T refer to the nucleic acids illustrated in the next figure. |
Figure 5.9 depicts the chemical structure of each of the nucleotide bases. They’re slightly more complex than the amino acids that make up proteins. As shown, the central part of each base forms a ring-like structure of atoms, much of the ring made of carbon (C), although some occasional nitrogen atoms (N) are present as well. A ring is a more intricate molecule that has essentially bent around to attach to itself; it becomes a little more stable that way.
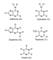 |
FIGURE 5.9 — Chemical diagrams of each of the 5 nucleotide bases. |
Although, at first sight, DNA seems an elaborate molecule, it’s really hardly more than a chain of 4 types of bases (Figure 5.9), which form the “rungs” of an extended structure resembling a twisted backbone, or “ladder” (see again Figure 5.8). Each rung of a DNA molecule consists of two interconnected (or paired) bases, giving this nucleic acid its famous double-helix structure. Experimental evidence shows, however, that all 4 bases do not bind together equally well. Cytosine always links with guanine, forming one of the two possible base pairs, while adenine links only with thymine, forming the other—C with G, and A with T, that familiar little jingle memorized by all beginning biology students. Figure 5.10 is a chemical schematic of each of these DNA base pairs. The structure of the ring-shaped molecules and especially their electromagnetic forces render incompatible any other combinations. In addition, also as shown in Figure 5.8, two side uprights, or strands, of the DNA ladder, made partly of sugars (carbon-hydrogen as well as phosphorous-oxygen compounds) that link the base pairs, help shape the DNA molecule.
| FIGURE 5.10 — Chemical diagrams of each of the two base pairs in the DNA molecule. The stippled area depicts where the link is located between the nucleotide bases. |
DNA is only one of many different kinds of nucleic acids, but it stands above all the rest because of one remarkable capability: DNA can copy itself—in effect, replicate. To understand this remarkable property, refer to Figure 5.11, which is a schematic diagram of the DNA molecule in the nucleus of a cell. Just prior to the division of a cell, the DNA molecule splits apart by unzipping right up the middle of the ladder. Nucleotide bases floating freely in the cell nucleus then link (with the help of a catalyst called an enzyme) with each of the broken strands. The result is two DNA molecules, where formerly there was only one. The fact that cytosine can bond only to guanine, and adenine only to thymine, ensures that the two “offspring” replicas are identical to the original “parent” DNA molecule. The newly assembled DNA molecules then retreat to opposite sides of the cell nucleus, after which the cell divides into two, with each new cell housing a complete set of DNA molecules.
| FIGURE 5.11 — Schematic diagram of a DNA molecule undergoing replication in the nucleus of a cell. |
Preservation of the exact structure of the original DNA molecule is the most important feature of replication. All the information about the specific duties of that type of cell—whether a blood cell, hair cell, muscle cell, or whatever—passes from an old cell to a newly created one. Accordingly, the biological function of the “daughter” cell remains identical to that of the “parent” cell (unless there is a rare copying error, or mutation). In this way, DNA molecules, whose functional units are the genes, are responsible for directing inheritance from generation to generation.
Just as for amino-acid sequences in proteins, the order of nucleotide bases as well as their number is paramount in the construction of nucleic acids. The sequence of bases along a nucleic-acid molecule specifies the physical and chemical behavior of that particular gene. In turn, all the genes of a living system collectively comprise a genetic code—an encyclopedic compendium of the physical and chemical properties of all the system’s cells and all its functions. In a very real sense, the two most important features of a living organism—its structure and its function—depend chiefly on the nucleic-acid molecules in the many nuclei of its cells, for these are the material entities that are passed on, or inherited, from one generation of cells to the next.
In analogy with another type of information storage—this Web site, for example—the individual bases can be considered words, the base pairs a sentence, and the whole DNA molecule a web of instructions. The words and sentences must be in the right order to give meaning to the Web site. An entire network of such instructional sites then comprises the genetic code for all the varied functions performed by any living organism. In short, a full set of DNA molecules is really information—a blueprint, or master plan, for every life form.
The nature of all living creatures is ultimately prescribed by the structure of their DNA molecules. These molecules specify, not only how one type of organism differs from another in both makeup and personality, but also how the physical and chemical events inside a cell properly coordinate so that the overall activity of the cell is as it ought to be.
At first glance, it would seem impossible that one type of molecule could do all this—namely, dictate the behavior of all the myriad life forms in the world today. After all, DNA has only 4 kinds of nucleotide bases. But DNA is the largest molecule known. In advanced organisms such as vertebrates, a DNA molecule can have as many as 108 bases or 1010 separate atoms, making the molecule nearly a meter (three feet) long if extended end to end; in humans, ~2m of DNA are squeezed into every human cell, and if all the DNA in a single person were unwound it would stretch ~109 km, or several roundtrips between Sun and Earth. In the above analogy where a DNA base equals a word, a single DNA molecule would resemble a 100-page manuscript. Consequently, huge numbers of possible combinations of bases guarantee a vast array of diverse living creatures, each with a different appearance, style, and personality. Yet, at the microscopic level, all creatures—without exception—are basically made of the same two dozen or so acids and bases, the very building blocks of life as we know it.
The common molecular content pervading all life on Earth is our best evidence that every living thing dates back to a single-celled ancestor—the so-called LCA, or Last Common Ancestor—billions of years ago.
Protein Synthesis Regarding our earlier query of protein synthesis, continuous production of the cytoplasm’s proteins makes heavy use of the cell’s nucleic acids. The sequence of events, illustrated in Figure 5.12, typically goes as follows: Just prior to cell division, the DNA molecule sends a related RNA molecule out of the biological nucleus and into the cytoplasm (Figure 5.12a). RNA stands for ribonucleic acid—a smaller, single-stranded version of the normally double-stranded DNA (wherein, for RNA, the thymine nucleotide base is replaced by the uracil base). The RNA molecule acts like a messenger, carrying instructions from the DNA molecule. Once in the cytoplasm, single-stranded RNA attracts freely floating amino acids to its uncoupled bases (Figure 5.12b). Only certain amino acids can successfully attach to the RNA bases, since the electromagnetic forces of RNA’s bases attract some amino acids, while repelling others. After some time—usually a few microseconds—the single-stranded RNA molecule fills its strand, partly by accidentally colliding and sticking, with an entire complement of proper amino acids. It’s not all chance, however; these acids also attach to one another by means of their own electromagnetic forces, which are governed by physical law (Figure 5.12c). Finally, when the long chain of amino acids is fully assembled along the entire length of the messenger RNA molecule, the chain detaches and drifts off into the cytoplasm of the cell (Figure 5.12d). A protein has thus formed. But, again, this is no ordinary protein created entirely at random. Rather, it’s a specific protein formed according to the instructions provided by the RNA molecule, taking into account both chance (the random collisions) and necessity (the linking forces). In this way, RNA acts as a prescription or template on which protein molecules are built—a template originating in the cell nucleus with the DNA molecule itself.
 |
FIGURE 5.12— This simplified sequence of steps, (a) --> (d), shows how proteins are made when the RNA molecule attracts, and then helps to link together, specific numbers and ordering of amino acids. Refer to the text for descriptions of each part of this figure. |
This, then, is a highly simplified account of the way that proteins are continually replenished in living organisms. All living systems grow and eventually become biologically stabilized in this same way. The whole process is occurring repeatedly in our bodies right now. Of course, different organisms have different genes and therefore manufacture different proteins—except for identical twins, which do have the same DNA structure. In reality, life is much more complicated, as a single gene doesn’t encode only one protein. One gene often yields a variety of proteins, which partly explains why humanity has hundreds of thousands of different proteins despite the so-called human genome—the sum of all our genes—containing only ~22,300 genes.
Genes and proteins: The first directs reproduction, the passage of heredity from one generation of life to the next. The second directs metabolism, the daily flow of incoming food (which is high-grade energy) and outgoing wastes (low-grade energy). While genes surely contain the recipes for making proteins, it’s the proteins that comprise the (structural) bricks and motor of cells and that do most of the (functional) work. Whether in man, mouse, or microbe, the genes mastermind life and the proteins maintain its well being.