| The raw cross-correlation data from SWARM
needs to be normalized by the auto-correlation, as part of the
calibration process. This normalization is performed by the
dataCatcher program, before the cross-correlation data is stored on
disk. Because the auto-correlation data is also stored, the
normalization can be undone in post processing, if need be. Although
the full (current) bandwidth of SWARM is (6/11)*2.288 = 1.248 GHz, there
are filters installed which pass only 1 GHz of the IF to SWARM. This
means that the amplitude of the auto-correlation spectra is extremely
low in the "guard band", the channels near both edges of the spectra.
There are ~ (1.248 - 1)*16384 = 4063 of these low amplitude guard band
channels. Normalizing the cross-correlation by dividing by the
auto-correlation dramatically raises the amplitudes (relative to the
good channels) as shown below, with SWARM s49 data on baseline 3-4 from
Saturday night's science track:

In principle, this should not make any difference. The guard band
channels are not supposed to be used for science anyway. But there is a
quirk in our data file format that makes this normalization
problematic. In our data files, the visibilities are stored as 16 bit
integers (one 16 bit int for the real part, one 16 bit int for the
imaginary part). A scale factor is stored for each chunk which allows
the 16 bit integers to be (approximately) converted back to the original
floating point value. This conversion to 16 bit integers reduces the
file size by approximately a factor of 2. We inherited this format
from OVRO, when we adopted the MIR format for our raw data files.
However, since there is only one scale factor for each chunk, all the
visibilites must be stored with values between 0 and 65535. Because
the normalized SWARM chunks had huge amplitudes in the edge channels,
most of the dynamic range of the 16 bit integers was used to express
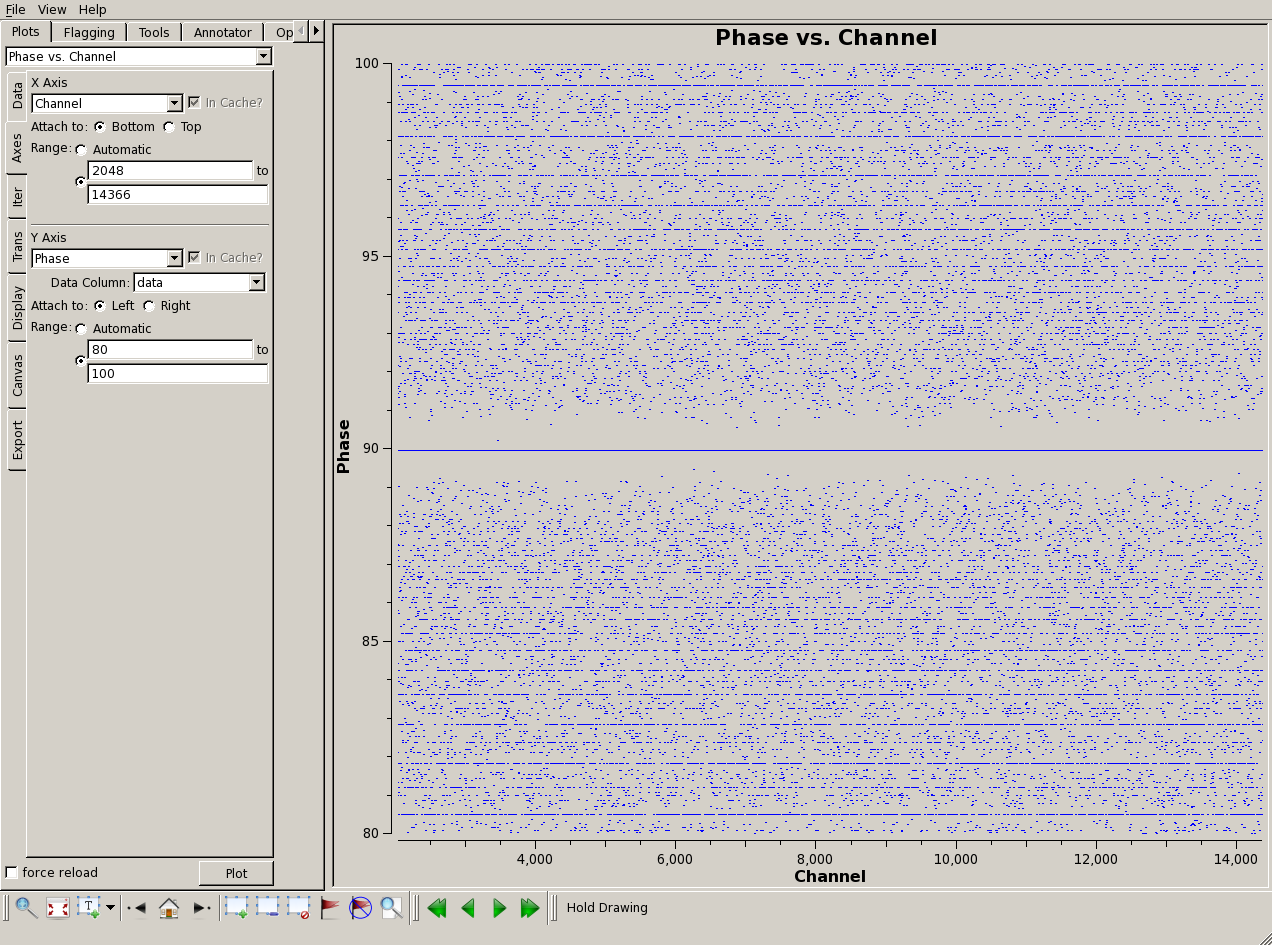
those very large values. The scientifically useful channels had to be
expressed in very few bits, leading to quantization of the amplitude and
phase, as shown below in a plotms() display from CASA:
The procedure by which the SWARM spectra are normalized was changed
yesterday (Apr 19) to solve this problem. The data in the
scientifically usable channels, the data in the IF regions 8-9 GHz
(s49) and 11-12 GHz (s50), are still normalized as they have been; they
are divided by the auto-correlation, channel by channel. The edge
channels outside the good parts of the spectra are still normalized, but
they are now normalized by the average value of the auto-correlation in
the good part of the IF. In other words, the guard channels are no
longer normalized by the corresponding channels in the auto-correlation,
they are all normalized by the same value, which is the average value
for the autocorrelation in the good part of the spectrum. This gets
rid of the huge amplitudes in the edge channels, as shown in the plot
below, produced from last night's science track:
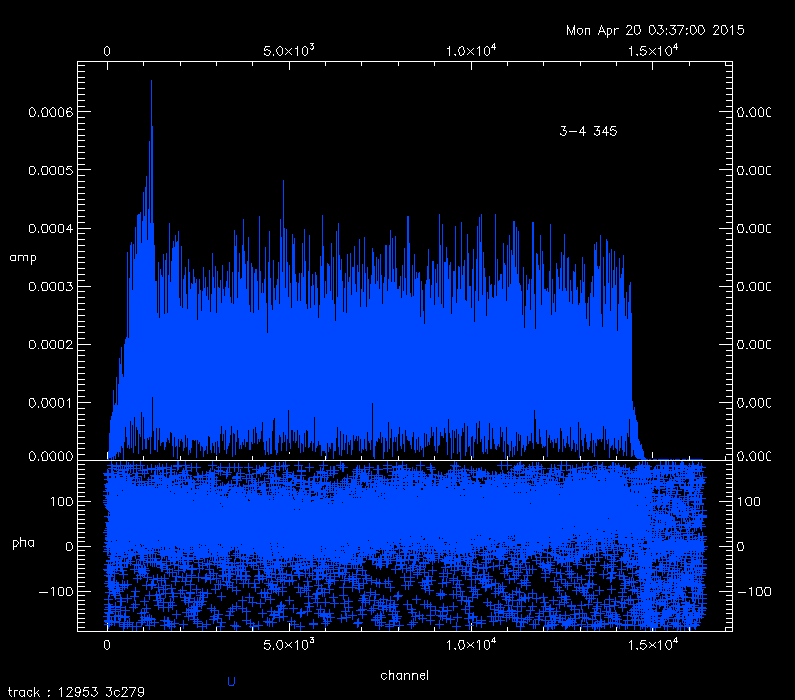
Notice in the plot above that there are discontinuities in the amplitude
at the transition from the good channels to the guard channels, because
of the differing normalizations. Of course the filters defining the
IF passbands are not infinitely sharp, and it is possible that we will
detect spectral features in the guard bands. If so, the
auto-correlations will need to be used to properly normalize those
channels in post-processing; by default, the guard channels will no
longer be correctly normalized.
When new filters are installed to increase SWARM's bandwidth, we'll need
to put the new filter widths in dataCatcher, so that all of the good
channels will be properly normalized by default.
|
