Querying multiple tables at the same time
Overview
Direct Joins - combine information of 1 to n tables directly
Helper queries - optimizing the speed for queries running on partitioned tables
Summary
Direct JOINs
So far we have only queried a single table, but the real power of databases lies in allowing us to join information from different tables. Each table may hold the data of a different survey. We will start with our 3 exoplanet systems we already used. This time we will query the master database for the newest TESS Input Catalog (TIC), located in the schema ticgaia. We already know the Gaia source_id for all three targets. Now, we find out if source_id is of any use. In order to do that, please open a second tab or window with this page, we will use:
Schemas, Tables, Connections
From top to bottom it contains a table of database schemas used in flemingdb, a table of all the public tables in flemingdb and last, not least a table of how all these tables are connected.
Go to the connections and press Ctrl-F in your browser window, type "source_id", press "Highlight All" and scroll to the bottom of the page. The last highlighted occurrence should be in the row starting with "ticlink_master" (the table name), followed by a list of keys in the second column and where they link to in the third column. The third column contains
gaiapk = gaiadr2.source_id
meaning that within ticlink_master the source_id from the gaiadr2 table is called "gaiapk" (pk = primary key, you will see that a lot). Using pgAdmin we can move in the tree on the left to
Servers -> Databases -> flemingdb -> Schemas -> ticgaia -> ticlink_master
Opening the SQL tab in pgAdmin your pgAdmin window should look like this:
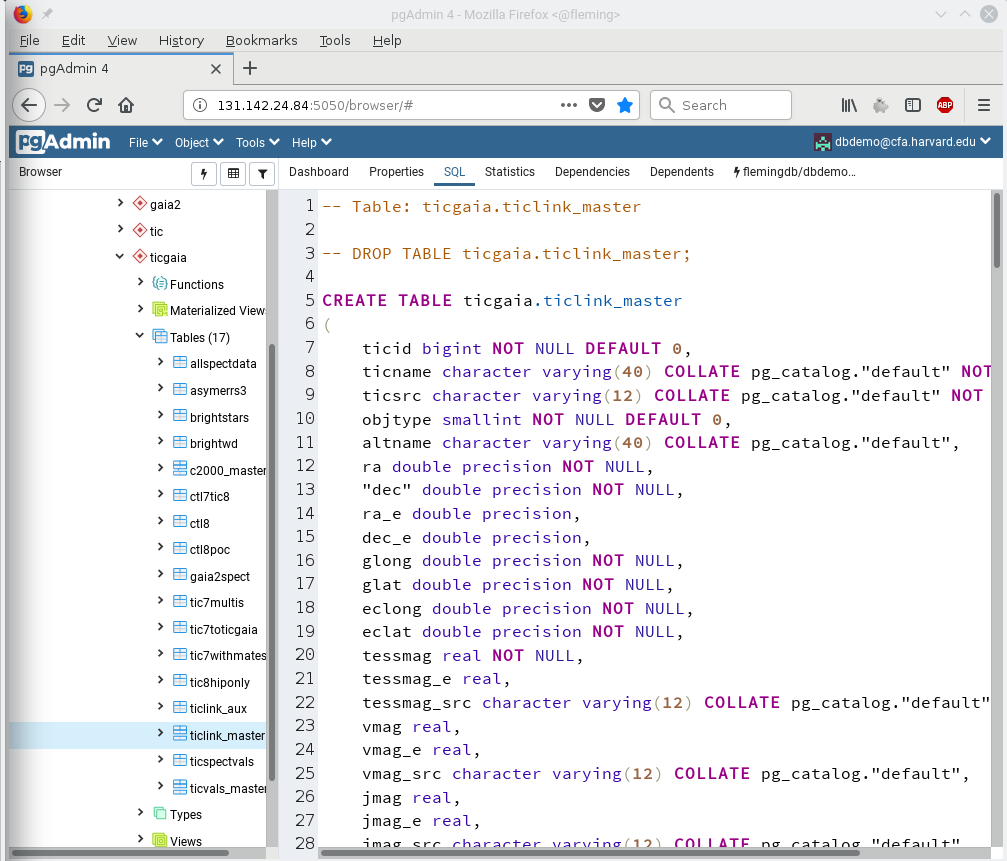
The Ctrl-F trick works in pgAdmin as well. Let's see what magnitudes we have: click on the SQL pane, press Ctrl-F and enter "mag". All occurences of mag will be marked. Scrolling down a bit you will find "gaiamag" in line 35. This allows us to formulate a first query. Open the query tool (Tools -> Query tool in pgAdmin), then copy and paste:
select ticid, gaiapk, gaiamag
from ticlink_master
where gaiapk in (4781196115469953024,
4623036865373793408,
1779546757669063552)
order by gaiamag;
Running it (lightning symbol) will result in our well known stars with their Gaia magnitudes. Two tables down from ticlink_master (tree view) is a ticvals_master storing more magnitudes, properties, extinctions, distances and a lot more. Feel free to explore, after that modify the query to
select ticlink_master.ticid, gaiapk, gaiamag,
dist, rad, mass, bestteff, bestteffsrc, gaiaqflag
from ticlink_master
join ticvals_master on (ticlink_master.ticid = ticvals_master.ticid)
where gaiapk in (4781196115469953024,
4623036865373793408,
1779546757669063552)
order by gaiamag;
Let pgAdmin explain what is going on by pressing the hand symbol. The result should look like this:
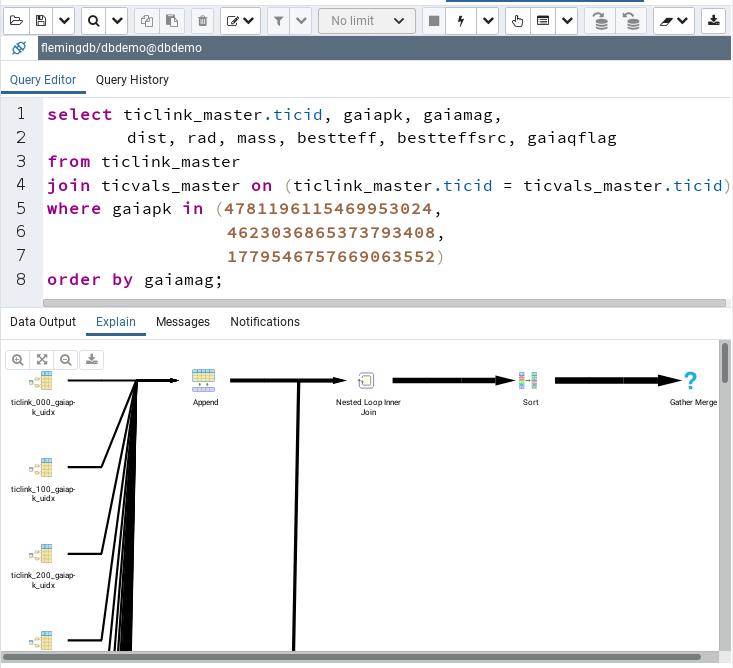
Mousing over the upper left symbol, it will tell you that postgres will perform an index scan (good) on ticlink_000 (ticlink_master and ticvals_master are partitioned). After the append symbol in the result pane comes another line from the bottom. Scrolling down far enough you will find that it will perform another index scan on the ticvals_master partitions. Then it combines the result in a loop and sorts.
Running the query (lightning symbol) will tell you the distance, radius, mass, best effective temperature and where we got it from for the 3 stars. Nice, but what did we do in this query?
Top down we changed
- select ticid to select ticlink_master.ticid
- added join ticvals_master on (ticlink_master.ticid = ticvals_master.ticid) directly after the from clause
The second point tells the database to join ticvals_master to ticlink_master. The on () construction tells it how to do it: we want the values of the column ticid in both tables to be identical. Because both tables contain a column ticid, we have to qualify the column names, here it is sufficient to just add the table-name in front. A fully qualified column name has the format
schema_name.table_name.column_name
Within one database the fully qualified name has to be unique. Because both tables have a column ticid, we need to qualify the name in the select part as well. If you forget that, postgres will complain and you get an error that ticid is ambiguous.
Please note that I added the gaiaqflag to the list. This is a compound Gaia quality flag consisting of astrometric and photometric information in Gaia DR2, if it is 1, everything is ok. If it is 0, you might see properties, but you should take them with a grain of salt and see them as rough estimate. Whenever you query stellar properties from TIC, be sure to get the gaiaqflag as well. There are some reasons why the TIC might be a better base catalog for your queries than Gaia DR2, please check the Notes on TIC and Gaia.
TIC has spectroscopic measurements from about 12 different catalogs and the last column already tells us that the bestteff is spect(roscopic) - the last one is coming from the Cool Dwarf Catalog (this catalog is fully integrated into TIC). We now want to see what we have as spectroscopic values and where they come from. Scrolling to the ticgaia section of Tables we find the most trusted values in the second last table: ticspectvals. So we join this table as well and by "ticspectvals.*" in the select part we query all columns in that table. Cut and paste the command:
select ticlink_master.ticid, gaiapk, gaiamag,
dist, rad, mass, bestteff, bestteffsrc, gaiaqflag,
ticspectvals.*
from ticlink_master
join ticvals_master on (ticlink_master.ticid = ticvals_master.ticid)
join ticspectvals on (ticlink_master.ticid = ticspectvals.ticid)
where gaiapk in (4781196115469953024,
4623036865373793408,
1779546757669063552)
order by gaiamag;
Please note that I join ticspectvals on ticlink_master.ticid as well, although I could have chosen ticvals_master.ticid instead and thus chain the first 2 tables. In general it is best practice to join on values from the first table (after the FROM clause) if you have a chance. In principle this allows the database to query the ticlink table first and once it has the result to query ticvals and ticspectvals in parallel. If chaining, postgres might wait for the ticvals result before it queries the spectroscopic table. Ok, let's run it. The result should be this:
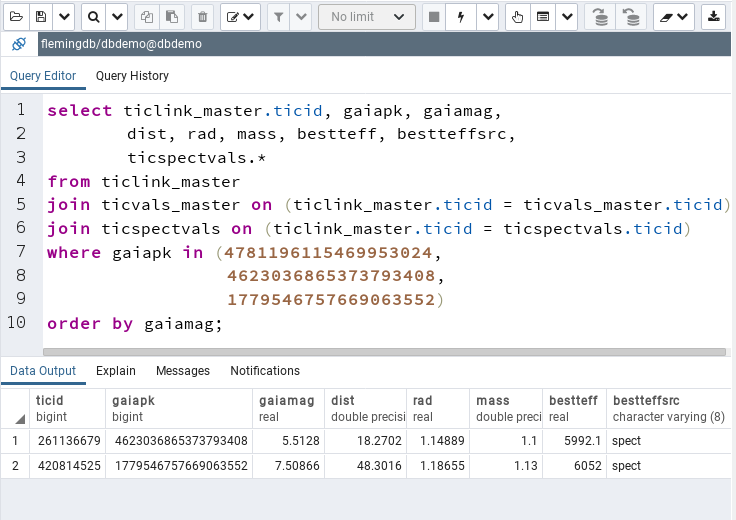
One of our stars disappeared, so what happened? Now, there are 4 different ways of joining tables and because we did not specify the way, postgres went with the default INNER JOIN. The 4 ways are:
- from A inner join B - object must be in BOTH tables to appear in the result (default)
- from A left join B - object only has to be in table A
- from A right join B - object only has to be in table B
- from A outer join B - every object from A is combined with every object from B. If A has n and B has m rows, the result has m * n rows
So we just left join the last table to take care of the problem
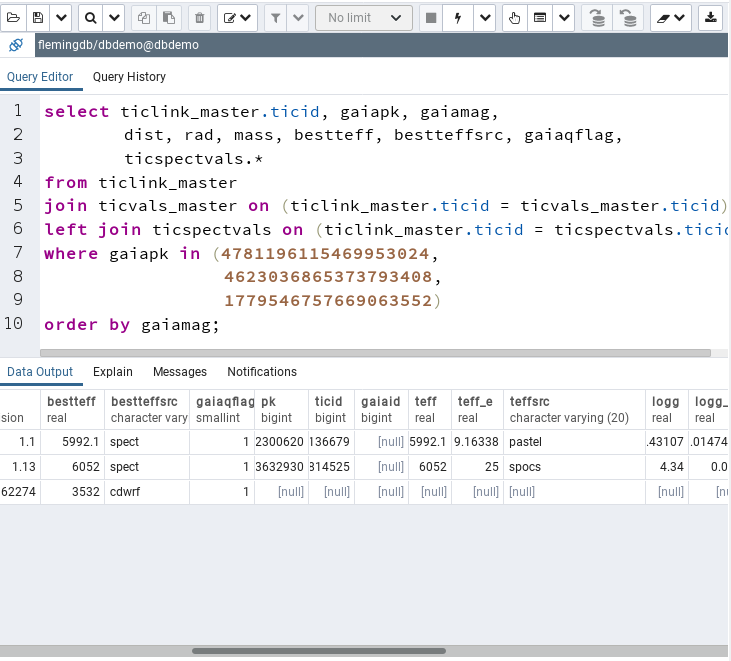
I scrolled the result a bit to the right, so that we can see the teffsrc column from ticspectvals. The first one comes from Pastel, the second from SPOCS.
Please note that our third star is back, but all spectroscopic values are reported as "null", indicating that we have no value. In fact null or NULL is a special SQL value used to indicate that a column has no value. You will often use conditions like
where column_name is not null
if you want to force the column in question to have a value. Attentive readers might have noticed that the "gaiaid" from ticspectvals is null for the first 2 stars although we definitely have a source_id from Gaia. Now, some of the spectroscopic catalogs came pre-matched to Gaia and thus have a gaiaid, Pastel, SPOCS and most of the others were not pre-matched, so we matched then ourselves.
Please note that there is a special form of INNER JOIN postgres allows you to use and you will find used on websites. Instead of
from ticlink_master
join ticvals_master on (ticlink_master.ticid = ticvals_master.ticid)
where gaiapk in (4781196115469953024,
4623036865373793408,
1779546757669063552)
we can write
from ticlink_master, ticvals_master
where gaiapk in (4781196115469953024,
4623036865373793408,
1779546757669063552)
and ticlink_master.ticid = ticvals_master.ticid
This second form runs only with postgres, the form I used here will work with any SQL database (Microsoft, Oracle, IBM, MariaDB etc and ASQL-online databases like MAST, SDSS, Gaia archive etc).
Helper queries
While postgres is pretty good in minimizing the runtime of your queries, you need to pay attention if you run queries joining large, partitioned tables as gaiadr2, ticlink (_master) etc. Copy this query into pgAdmin:
select *
from sdssdr9_best_neighbour
join ticlink_master
on (sdssdr9_best_neighbour.gaiaticid = ticlink_master.ticid)
join ticvals_master
on (sdssdr9_best_neighbour.gaiaticid = ticvals_master.ticid)
where sdssdr9_best_neighbour.gaiaticid >= 0 and
sdssdr9_best_neighbour.gaiaticid < 10000000;
Then let pgAdmin explain the query plan (hand symbol) and mouse over the first symbol:

We get a Seq(uential) Scan over all partitions of ticlink_master. Remember: that is what we do not want to see. If you scroll down to the ticlink part, you will find that it is fine there: index scan. So what is going on?
Now, the answer is, that the query planner in postgres is not yet fully optimized for queries joining large, partitioned tables and sometimes just gets it wrong. That is one reason while you should always look at the output of Explain when querying large tables. Your query will run, no matter what, but take much, much longer, because we are sequentially reading 1.7 billion rows from ticlink here. Postgres version 12 will have a better optimization for querying partitioned tables, but this version will only come out in late 2019. But: fortunately we can help postgres if it gets it wrong. Consider this query:
with helper as
(select *
from sdssdr9_best_neighbour
where sdssdr9_best_neighbour.gaiaticid >= 0 and
sdssdr9_best_neighbour.gaiaticid < 10000000
)
select *
from helper
join ticlink_master on (helper.gaiaticid = ticlink_master.ticid)
join ticvals_master on (helper.gaiaticid = ticvals_master.ticid);
It is semantically identical to the first one, means: it will produce the exactly same result, but much faster because now we have Index Scans on ticlink and ticvals (output scrolled so that you see at least the arrows, widths are identical):

So what is the trick here? In the first version we restrict the number or resulting rows in the WHERE clause to be 10 million at max by requiring ticid to be between 0 and 10 million. The second version takes this restriction and puts it in a helper query - something we are allowed to do in Postgres and we can name them freely, use "xyzzy" instead of "helper" if you like:
with helper as
(select *
from sdssdr9_best_neighbour
where sdssdr9_best_neighbour.gaiaticid >= 0 and
sdssdr9_best_neighbour.gaiaticid < 10000000
)
Please note the () around the select. In the second part we take the result from this helper query and use it to join the big guys (remember: "select *" means "give me all columns from all tables, helper queries included):
select *
from helper
join ticlink_master on (helper.gaiaticid = ticlink_master.ticid)
join ticvals_master on (helper.gaiaticid = ticvals_master.ticid);
This way postgres does notice that is has to query ticlink and ticvals by a limited amount of ticids and factors that in for both joins.
The helper version of this query runs 10 times faster than the first version. Thus by checking your queries via explain and using helper queries if postgres gets it wrong, you can shove of 90 % of the runtime. If you want to run this query, please do not do so in pgAdmin. Instead copy and past the following into a textfile named "withhelper.sql":
copy
(
with helper as
(select *
from sdssdr9_best_neighbour
where sdssdr9_best_neighbour.gaiaticid >= 0 and
sdssdr9_best_neighbour.gaiaticid < 10000000
)
select *
from helper
join ticlink_master on (helper.gaiaticid = ticlink_master.ticid)
join ticvals_master on (helper.gaiaticid = ticvals_master.ticid)
)
to stdout
with csv header delimiter ',';
and ssh into flemingdb. Tcshell users then use this command line:
nohup tshtime dbdemo -f withhelper.sql > nhwithhelper.csv &
while bash users use this command line:
nohup bshtime dbdemo -f withhelper.sql > nhwithhelper.csv &
It should deliver 1,072,030 lines in under 2 minutes. With "tail nhwithhelper.csv" you will find the runtime in the last line. "tshtime" and "bshtime" are two other useful tools found in /home/mmtobs/local/bin. They measure the runtime of shell commands, the bash version in ms, the tsh version only in s. And: congratulations! You just ran your first query yielding more than 1 million lines.
If you ask me, helper queries are a very useful thing, not just for big tables. They often help to isolate the most restrictive condition and while running test queries, it is often easier to restrict the helper than to do it in a convoluted bunch of conditions in the WHERE clause ending multiple joins. To end the story: you can have as many nested helper queries as you need. However, at one point in time queries may get so complex, that creating an intermediate table in the tmp-shema is the right thing to do.
Summary
- Information from several tables are combined by using FROM A JOIN B ON (condition)
- There are 4 different ways the result is generated:
- from A inner join B - object must be in BOTH tables to appear in the result (default)
- from A left join B - object only has to be in table A
- from A right join B - object only has to be in table B
- from A outer join B - every object from A is combined with every object from B. If A has n and B has m rows, the result has m * n rows
- Never use an OUTER JOIN without being very, very sure that you need it.
- Whenever possible use columns from table A in the ON part
- The number of tables you can join is not limited, although you might think about creating a table in the tmp-schema if you are joining many or big tables. These intermediate tables often save a lot of time if you need the information repeatedly. Running a query on an intermediate table is often faster than joining everything again and again.
- What tables FlemingDB has is documented in Schemas, tables and connections.
- Once you know which tables you want to join, look for columns in both tables that store the same value. At first this is admittedly the hardest part. However, the connection part of Schemas, tables and connections may come to the rescue. Look for the main table (directly after FROM), then see if it is linked to the table you want to join by reading the "Linked to" column.
- Check your query via Explain (hand symbol) - very important if joining partitioned tables.
- You may help postgres optimizing queries joining partitioned tables by putting the most restrictive condition in a helper query (runs about 10 times faster):
with helper as
( select ...
from ...
where ...
)
select ...
from helper
join ...
...
where ...
As usual: in case of remarks, questions or if you need help with putting a query together, please email DBAdmin.


